
- Deivison Viana
- 0 Comentários
- 591 Pontos de vista
Configurando Seu Ambiente
Preparando-se com as Ferramentas Certas
Para iniciar este tutorial, você precisará de alguns softwares específicos. No centro da nossa configuração estão o Docker Engine e o Docker Compose:
- Docker Engine ajuda a containerizar suas aplicações, tornando-as portáteis e fáceis de executar em qualquer sistema.
- Docker Compose facilita a execução de aplicações Docker multi-contêiner. Você define e inicia todos os serviços a partir de um único comando.
Se você está configurando isso pela primeira vez, o Docker Desktop simplifica o processo, agrupando o Docker Engine e o Compose. Está disponível para Windows, macOS ou Linux.
Após a instalação, confirme se tudo está funcionando executando docker-compose --version no seu terminal. Nota, para usuários de Mac com chips M2, você precisará do Rosetta 2. Basta executar softwareupdate --install-rosetta em um terminal, e não se esqueça de habilitar o Rosetta nas configurações do Docker Desktop em Configurações → Geral.
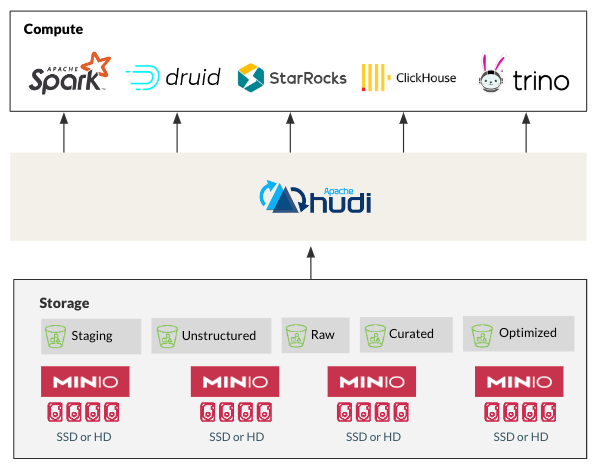
Unindo HMS e MinIO
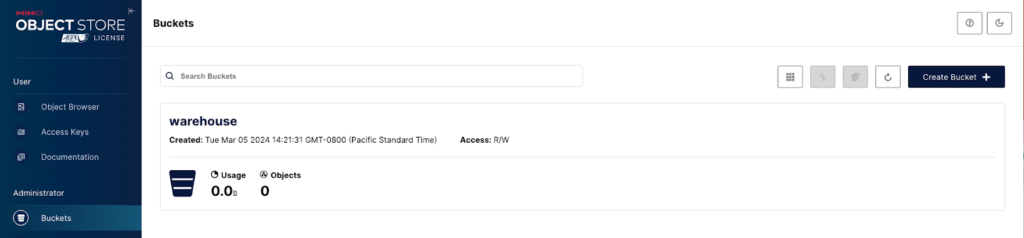
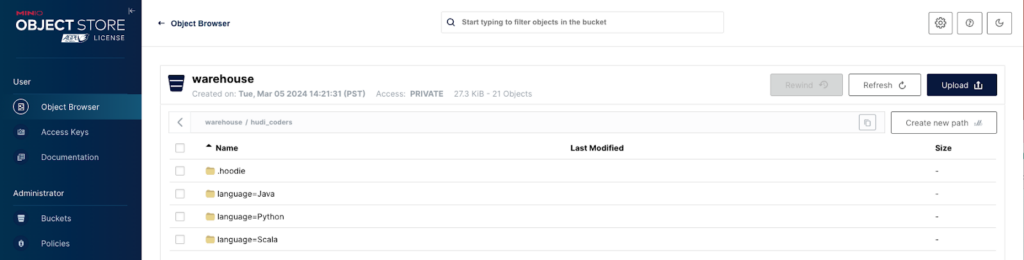
Este tutorial prático utiliza o repositório de demonstração do StarRock. Comece clonando o repositório. Com seu terminal apontado para o diretório documentation-samples/hudi, inicie a configuração com docker compose up. Esta ação inicia o StarRocks, HMS e MinIO.

Visite o Console MinIO em http://localhost:9000/ e faça login usando admin:password. Você verá um bucket warehouse pré-criado, sinalizando um início bem-sucedido.
Inserção de Dados com Spark Scala
Acessando o contêiner spark-hudi, entre no ambiente REPL do Spark para começar a manipulação de dados. Aqui está um resumo rápido:
- Comece executando
dockerexec -it hudi-spark-hudi-1 /bin/bashseguido por/spark-3.2.1-bin-hadoop3.2/bin/spark-shell. - Dentro do shell do Spark, execute comandos Scala para configurar seu banco de dados e tabelas, e então inserir dados.
Aqui está um exemplo de configuração de esquema e processo de inserção de dados:
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import scala.collection.JavaConversions._
val schema = StructType(Array(
StructField("linguagem", StringType, true),
StructField("usuários", StringType, true),
StructField("id", StringType, true)
))
// Defina seus dados
val rowData= Seq(
Row("Java", "20000", "a"),
Row("Python", "100000", "b"),
Row("Scala", "3000", "c")
)
// Crie um DataFrame
val df = spark.createDataFrame(rowData, schema)
// Configurando e salvando os dados
df.write.format("hudi").
option("nome da tabela", "nome_da_sua_tabela").
... // Configurações adicionais
save("s3a://warehouse/seu_caminho_de_dados")
Isso conclui o nosso tutorial de inserção de dados. A seguir, você aprenderá sobre como explorar esses dados e extrair insights.
O conteúdo completo revisado, junto com guias detalhados para cada segmento, será disponibilizado em breve, garantindo uma compreensão abrangente sobre a configuração e gestão de datalakes modernos com Hudi, MinIO e HMS.
val hudiDF = spark.read.format("hudi").load(basePath + "/*/*")
hudiDF.show()
val languageUserCount = hudiDF.groupBy("language").agg(sum("users").as("total_users"))
languageUserCount.show()
val uniqueLanguages = hudiDF.select("language").distinct()
uniqueLanguages.show()
// Stop the Spark session
System.exit(0)





{kind=link}